# 自我介绍
回答参考:
- 【基本情况】名称学历年龄一句话,原公司业务一两句,岗位和工作内容,个人技能。
- 【行业认知】对面试公司产品方案的理解,客户是谁,应用场景是什么,行业特点 / 认知、竞品、上下游。提前准备好,表现出你对这场面试是有准备的、对这家公司业务是有调研、对这个行业是有认知的,区别于盲目求职。
- 【个人规划】为什么想转行 / 跳槽,为什么投这家公司。
# 高可用、高可靠、容灾,这三个有什么区别?
高可靠:系统本身不容易坏
高可用:坏了也能继续服务;切到别的机器,用户几乎感觉不到
容灾: 整个机房挂了还能恢复
高可用通常解决单机或服务故障,
容灾解决的是机房级或地域级灾难。
# 为什么不卖裸金属,而是要虚拟化?
“面试官您好,这个问题非常经典。作为售前,我们在给客户推荐方案时,技术没有绝对的好坏,只有场景的适配 。我们之所以在绝大多数场景下主推虚拟化(或云化)而不是裸金属,主要是基于客户的商业价值、业务以及运维这三个核心维度来考量的。具体来说有以下几个原因:”
# 为什么要虚拟化?(打客户痛点)
# ① 降本:打破 “资源孤岛”,大幅降低 TCO(总拥有成本)
- 裸金属的痛点: 传统裸金属架构下,一台服务器通常只跑一个核心应用(One App, One Server),CPU 和内存的平均利用率往往只有 10%-20%,造成极大的硬件浪费。同时,机房空间、电力、制冷成本居高不下。
- 虚拟化的价值: 通过资源池化,我们可以把硬件利用率提升到 70%-80%。客户只需要买更少的物理机,就能跑更多的业务。这不仅节省了硬件采购成本(CapEx),还大幅降低了长期的机房运营成本(OpEx)。
# ② 增效:极致的业务敏捷性,缩短 TTM(产品上市时间)
- 裸金属的痛点: 如果业务部门需要上线新系统,采用裸金属意味着:提采购流程 -> 等待物流 -> 硬件上架 -> 连线 -> 装系统,整个周期可能长达几周甚至几个月。
- 虚拟化的价值: 虚拟化实现了软件定义。交付一台虚拟机只需要几分钟。业务高峰期可以秒级弹性扩容,业务低谷期可以回收资源。这让 IT 部门从 “业务的瓶颈” 变成了 “业务的加速器”。
# ③ 控险:硬件解耦,保障极高的业务连续性(HA/DR)
- 裸金属的痛点: 硬件终究会坏(主板坏、内存宕)。在裸金属环境下,硬件宕机意味着业务中断,恢复起来非常耗时。
- 虚拟化的价值: 虚拟化将操作系统和底层硬件解耦了。通过热迁移(Live Migration)、高可用(HA)、快照等技术,即使底层某台物理机冒烟了,虚拟机也能自动在另一台物理机上拉起,甚至做到用户无感知。这种级别的容错和灾备能力,纯裸金属是很难低成本实现的。
# ④ 运维:统一管理,降低运维复杂度
- 管理 100 台裸金属和管理 1000 台虚拟机是完全不同的概念。虚拟化平台提供了统一的控制台(单点登录、统一监控、自动化运维脚本),大幅降低了 IT 人员的运维压力,让他们有精力去关注更贴近业务的上层创新。
# “不(全)卖” 裸金属?(谈场景边界)
“当然,作为一名客观专业的售前,我并不会说裸金属一无是处。我们不主推裸金属,是因为它不适合‘普适性’的业务,但它在特定场景下依然是不可替代的。 如果客户有以下需求,我依然会向他们推荐裸金属方案:”
- 极致的性能要求: 比如核心的 Oracle RAC 数据库、大型高频交易系统(量化交易),虚拟化层(Hypervisor)带来的 3%-5% 的性能损耗是客户无法忍受的。
- 特殊的硬件依赖: 某些特定的高性能计算(HPC)、重度 GPU 渲染、或者需要直通特定物理外设的场景。
- 严苛的合规与安全物理隔离: 某些金融或政务客户,受限于监管要求,某类数据必须存放在绝对物理隔离的服务器上,不能与其他业务共享物理资源。
(注:现在也有 “裸金属云 / BMS” 的概念,如果面试官追问,你可以补充说现在的云厂商也提供自动化交付的裸金属服务,结合了物理机的性能和虚拟机的敏捷,这是技术演进的结果。)
# 总结升华(展现售前价值观)
“总结来说,我们卖的不是虚拟化软件,也不是物理服务器,而是解决客户问题的方案。 虚拟化能解决 80%-90% 的企业日常 IT 痛点,带来最高的 ROI(投资回报率),所以它是我们的主力方案;而对于剩下 10%-20% 的核心高并发、高合规场景,我们会用裸金属去托底。为客户设计‘虚拟化 + 裸金属’的混合架构,实现成本与性能的最优解,这才是售前的核心价值所在。
# 百度专项
制造业,政务,交通
# 概念
昆仑芯 P800: AI 加速芯片(NPU 类)
“开物” 工业互联网平台、“文心” 大模型、“千帆” 大模型平台、百舸异构算力平台
3C:3C 电子行业,计算机、通信、消费电子
ERP:管接订单、算物料、排计划
MES:制造执行系统,管车间现场怎么把产品造出来
PLC / 设备:管机器怎么动
# 产品体系

# 怎么把一个 72B 的模型在云上部署
- 算显存,72B 模型如果用常规的半精度(FP16)加载,大约需要 144GB 的显存。考虑到推理时还需要上下文缓存(KV Cache),单张主流的 80G 显卡(比如 A100/H100)肯定是放不下的。因此,我会选择多卡张量并行(TP) 的方式,至少需要 2 到 4 张 80G 的 GPU 卡组成一个推理节点。
- 选平台,平台内置了丰富的模型环境镜像,支持一键部署,能帮客户省去繁琐的 CUDA 环境配置时间,实现快速验证和上线
- 补齐短板,强调网络与存储,大模型推理对网络和存储的要求极高,CFS 分布式存储,VPC 网络
# MCP
MCP(Model Context Protocol)就是:让大模型 “安全、标准地调用外部工具和数据” 的协议。
因为有的 tool 很多 agent 都需要,所以将 tool 作为服务托管在云端,然后 agent 来调用
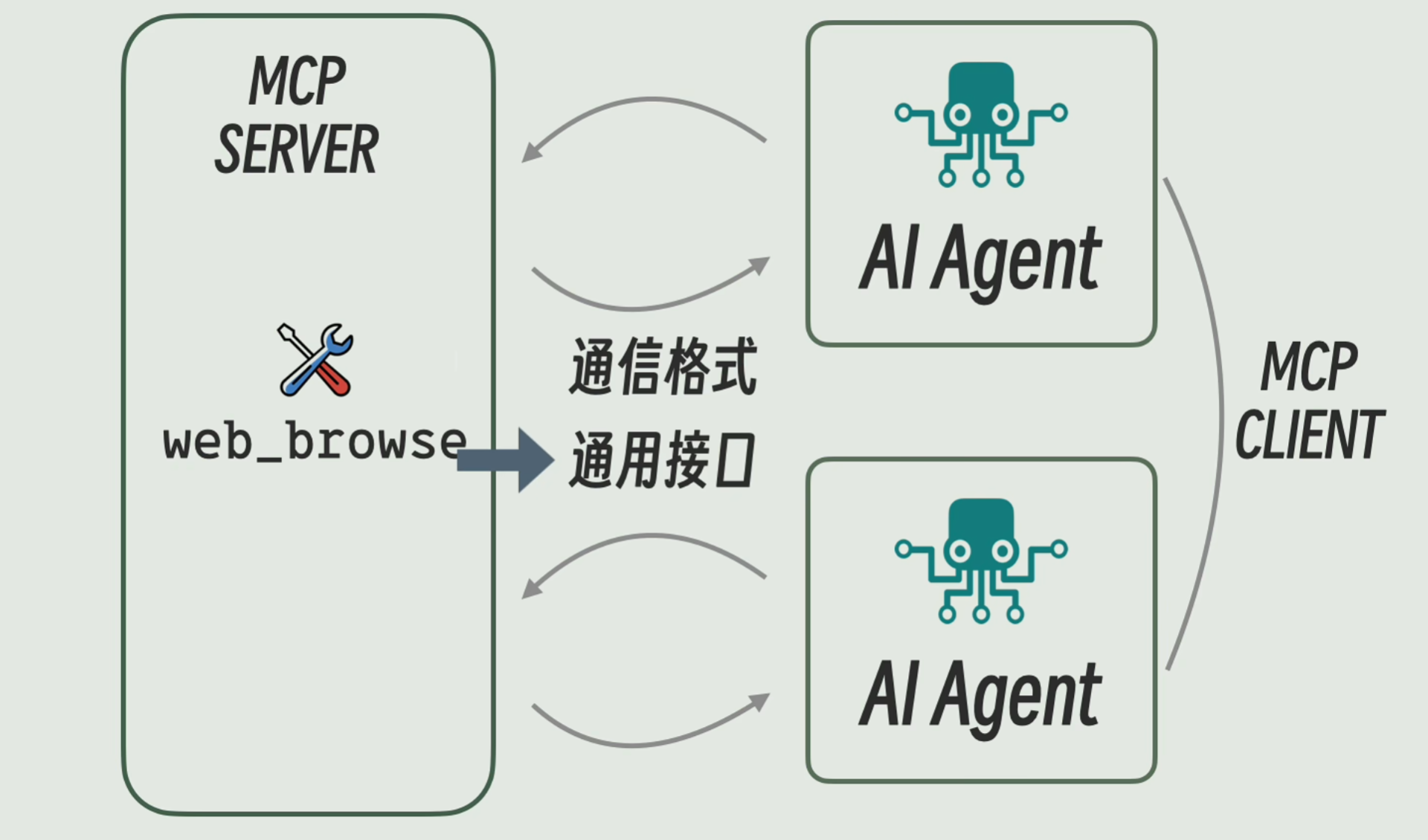
MCP 定义了 server 和 client 的
- 通信格式(如何通信)
- server 中有什么接口(查询有那些 tool、tool 的功能描述、需要的参数)
MCP server 还可以提供数据、文协读写服务(resources)、提示词模板(prompt)
MCP server 可以在 agent 的本机部署,使用 stdio 通信;也可以部署在网络上,通过 HTTP 通信
# 上下文工程
提示词工程(Prompt Engineering):通过系统提示词和用户提示词的组合,引导 ai 返回特定风格回复
在提示词举例子:few-shot
只行为约束,无例子:zero-shot
ai 自己分解任务,一步步推理:COT 思维链
上下文:和 ai 的对话记录实际保存在 agent 处,这个被一次性发给 AI 的完整的历史记录被称为上下午 context
上下文管理:如何管理和修改这段历史记录的技巧,主要由于 agent 能自己调用 tool 了,用户无法直接管理上下文

- 增加记笔记 tool
transformer 架构对输入的开头结尾信息很敏感
- 裁剪压缩 prompt
- 丢掉较老信息
- 大模型对较老信息做 summary
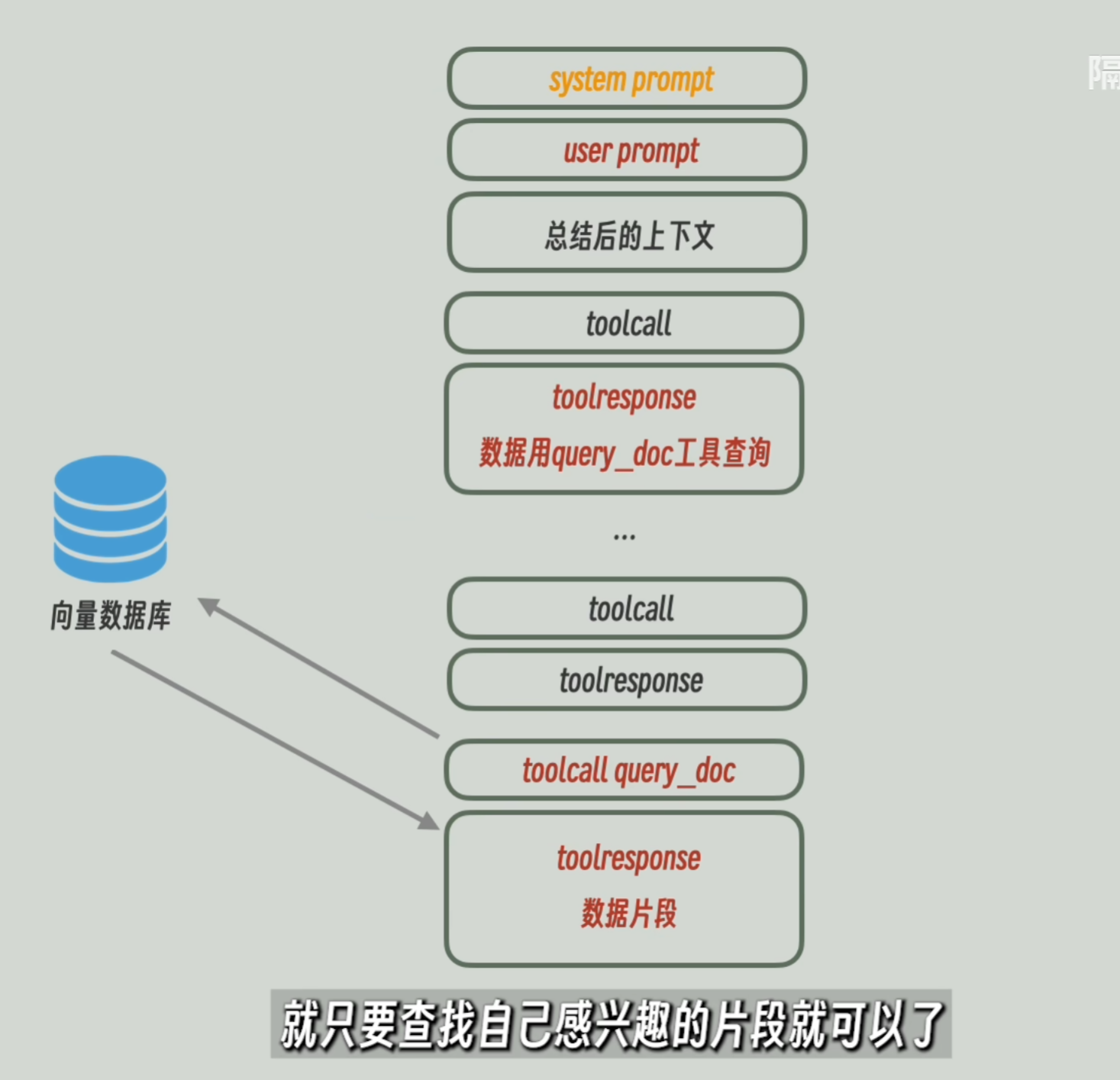
- 较长 toolresponse 处理后存入临时向量库,用 query_doc 工具查询
- 优化工具返回值,比如扔掉不必要的 html 标签
# 售前和开发什么区别
KPI 不同
售前:以成单,推进项目,赋能销售(更抽象),对客户业务理解
开发:写代码开发 api,需求的按时完成(产出),可以量化
# 售前不被 ai 取代的原因
日常工作上:客户汇报等接触交流场景(尊重,核心),写文档等书面工作(提效)
解决方案上:结合客户业务场景(新场景,最核心),AI 没法设计新场景(必须使用本地知识库)
腾讯:生态最好,B2C,微信企微,零售电商
阿里:对高并发、性能、底层研究投入多,性能最好
字节:后发,AI 大模型超强
# LLM 科研助手深挖
-
明确区分你做的和团队做的(比如你负责架构设计和选型,别人负责写前端)。
-
解释选型逻辑:可以结合前面提到的 DeepSeek 32B 性能好、逻辑推理强,且 4-bit 量化后单卡 24G 显存就能跑,性价比极高。
-
强调 “私有化部署” 是为了解决 “数据隐私(科研机密)” 痛点,这非常契合企业级客户的需求。
-
核心逻辑: RAG 用来补充 “动态的、外部的业务知识” (如最新的科研论文、具体的实验数据);LoRA 用来学习 “特定的语言风格、指令遵循和回复格式” (如让模型学会用严谨的学术口吻、特定的 JSON 结构输出)。
# Q1
问:
你们用的 deepseek 32b Q8 这个大小有多大?用来推理时两张 rtx4090 够用吗显存?你们用 2000 条问答对来做指令微调,4 遍, Lora 微调训练了多久?
答:
-
我们使用的是 Q8(8-bit)量化版本。在 8-bit 量化下,每个参数占用 1 个字节(Byte)。因此,模型权重本身的大小大约在 32GB 到 34GB 之间。
-
两张 RTX 4090 显存够用吗?完全够用,总显存是 24GB * 2 = 48GB,模型权重占用约 32GB~34GB,剩下的 14GB~16GB 显存完全可以留给推理时的上下文缓存(KV Cache)和系统开销。
硬件成本(几万块钱)远低于采购企业级显卡(如 A800/H800),非常契合科研团队的预算痛点。
- 由于 2000 条数据量相对较小,且我们使用的是 LoRA(低秩微调),只更新了模型中极少部分(通常小于 1%)的参数,因此训练速度非常快。在双卡 RTX 4090 环境下,张量并行,结合 LlamaFactory 的 DeepSpeed Zero3 (或 FSDP) 加速,平均序列长度在 1024 左右时,跑完 4 个 Epoch 大约只需要 1.5 到 2 个小时。
# Q2
问:
你们微调的数据怎么来的?听你们说用了 neftune,一共 2000 条问答对,那对于每个问答,你们的 input 怎么处理?怎么 chunk?你们说还掺杂了一些通用问答对,这个通用问答的来源是哪里?
答:
NEFTune 其实不是用来生成数据的工具,而是在微调训练时,向 Embedding 层添加随机噪声的一种技术,目的是防止模型过拟合,提升指令跟随能力。
-
我们这 2000 条核心科研问答对的真实来源是 “Self-Instruct(自我指令生成)” 结合开源学术数据
- 我们收集了一批高质量的开源学术论文(PDF/XML 格式)和科研写作指南。
- 利用能力更强的闭源大模型(如 gemini 或 claude opus),编写特定的 Prompt(如:“请根据以下论文摘要,生成 3 个科研人员可能会问的深度问题及专业解答”),批量生成了这批高质量的垂直领域问答对。
-
LlamaFactory 的标准指令微调格式中,数据通常包含
instruction(指令)、input(上下文输入)和output(回答)
- Chunk(切分)策略: 学术论文通常很长,不能直接塞进去。我们使用解析工具(如 PyMuPDF 或 Marker)提取文本后,按语义段落或章节进行 Chunk。为了保证上下文连贯,Chunk Size 通常设定在 512 到 1024 Tokens,并且设置了约 100 Tokens 的 Overlap(重叠)。
- Input 的处理: 切分好的 Chunk 文本就会作为
input字段的内容。instruction则是用户的提问(例如:“请总结这段文献的研究方法”),output则是大模型生成的标准答案。这样训练出来的模型,在 RAG 阶段检索到相关 Chunk 时,就能非常精准地根据 Input 提取信息。
-
掺杂的 “通用问答对” 来源(例如 Alpaca-GPT4-zh、COIG-CQIA 或清洗过的 ShareGPT 数据集)中,抽取了约 10%~20% 的日常对话、逻辑推理和代码问答数据。
这样做是为了防止大模型出现 “灾难性遗忘(Catastrophic Forgetting)” 。如果只用科研数据微调,模型可能会变成一个只会读论文的 “书呆子”,连简单的 “你好”、“帮我写封邮件” 都不会回答了。掺杂通用数据,能保证模型在具备科研专业能力的同时,依然维持良好的通用对话智商。
# Q3
问:
我看到你同时用了 RAG 和 LoRA 微调。在实际落地中,你是怎么界定哪些数据用来做 RAG 知识库,哪些数据用来做 LoRA 微调的? 这两者的边界在哪里?有没有遇到微调后模型能力遗忘,或者 RAG 检索召回率不高的问题?RAGFLOW 的 pdf 文档解析能力怎么样?
答:
-
RAG 管事实与知识(开卷考试),动态更新快、长尾碎片化、需要精确溯源的 “事实型” 数据。;LoRA 管风格与逻辑(内化能力), 固定的输出格式、特定的思考范式、垂直领域的专业黑话。
- 走 RAG 数据:实验室最新的内部科研报告、几万篇细分领域的 PDF 参考文献、仪器操作手册。
- 走 LoRA 数据:我们微调的数据主要是 “如何写文献综述的结构”、“如何从摘要中提取创新点”、“如何用学术严谨的口吻回答问题”。
-
早期只用科研指令微调时,模型确实变成了 “学术机器”,连写一封普通的请假邮件都会用写论文的语气,甚至丧失了部分代码能力。所以我们
- 引入了 15%-20% 的通用高质量问答对(如闲聊、逻辑推理、代码)进行混合训练
- 严格控制 LoRA 的秩(Rank,通常设为 8 或 16)和 Alpha 值,防止微调权重过度覆盖 DeepSeek 32B 原本强大的底座能力。
-
科研提问往往很口语化,而论文原文很书面化;或者用户搜一个缩写,召回不到全称,导致 “明明库里有,但搜不出来”。
- 混合检索。 我们没有单靠向量检索(Embedding),而是结合了传统的 BM25 关键词检索。向量负责语义泛化,BM25 负责专业术语的精准匹配。
- Query 意图重写。 在用户提问进入 RAG 之前,先让大模型把用户的短问题 “扩写” 或 “翻译” 成更丰富的检索词,极大提升了召回的命中率。(可以想到,但我们没做)
- RAGFlow 是我们项目的一个亮点,我对它的评价是:在处理复杂学术文档(特别是 PDF)时,它是目前开源方案里比较合适的一个,但也有其代价。
-
他的文档解析模块正式名称叫 "DeepDoc" ,包含 vision 和 parser 两个部分。它能够识别版面布局、分栏和表格,能区分哪部分是标题、哪部分是双栏(不会把左栏和右栏的字混在一起读),甚至能把表格还原成 Markdown 格式,把公式转成 LaTeX 代码。这对于科研场景来说是硬核刚需
vision 是 DeepDoc 底层的计算机视觉(CV)能力集合,只负责「看懂文档图像」,不关心文档本身的格式类型,核心解决「文档页面里有什么元素、元素在哪里、是什么类型、内容是什么」的问题。
parser 是面向具体文档格式的解析实现集合,负责「读懂完整文档」,是用户最终调用的解析入口。 他调度 vision 能力,核心解决「这个文档是什么格式、该用什么策略解析、怎么把零散的元素拼成有完整语义的结构化内容」的问题。
-
算力消耗大,用的是他们家自研的基于 ONNX 的版面识别模型(LayoutRecognizer) ,解析 PDF 的速度比纯文本提取慢得多,且需要消耗一定的 GPU 或 CPU 算力。
知识库的构建(入库阶段)可以放在夜间或利用闲置算力异步处理。虽然入库慢一点,但换来的是问答阶段极高的准确率,这是完全值得的。
# Linux 的四种探针是什么
# 什么是探针
“探针”,本质上就是:在不让系统停工的前提下,往关键位置放 “监控摄像头” 或 “质检员”,看看到底是谁在忙、哪里堵了、哪道工序最慢。
用技术一点的话说,探针 就是在程序执行的某个位置,放一个观察点 / 打点 / 挂点。当代码运行到这里时,我们就能:
- 记录它有没有被执行
- 记录执行了多少次
- 记录耗时多久
- 看参数、返回值、调用链
- 判断瓶颈在哪里
可以把它理解成:
- 探针 = 摄像头安装位 / 质检员站位
- 观测程序(比如 eBPF 程序)= 真正在那里记笔记、统计、上报的人
# 四种探针
# 其实就是一个 2×2 分类
只要记住两个维度 ——
-
维度 1:看哪里?
-
看内核:看厂长和核心机器在干什么
-
看用户态:看车间工人和业务程序在干什么
-
-
维度 2:怎么放监控?
-
动态探针:临时贴上去的摄像头,不是工厂设计时就有,而是你排障时临时加的
-
静态探针:工厂建好时就预留的观察窗,设计者提前在关键位置留好了标准监控点
-
注意:
“动态 / 静态” 说的是 “监控点怎么来的”,不是说程序是不是在动态运行。
于是就有了这张最重要的表:
| 观察对象 | 动态:临时贴摄像头 | 静态:出厂留观察窗 |
|---|---|---|
| 内核 / 核心机器 | kprobes | tracepoints |
| 用户态 / 车间工人 | uprobes | USDT |
假设现在有人说:
“我们的网站越来越慢了。”
你作为工厂排障的人,观察时会 先内核后程序,先静态后动态(tracepoints、kprobes、USDT、uprobes)
# 销售、售前、售后
销售:皮实、人际关系交往
售前:逻辑思维、清晰表达,持续学习(从自家产品到整个行业)
售后:(包含交付、项目经理、实施开发测试),沟通能力要强,具体定位见下述章节
# 从具体业务流程梳理
销售签了合同,30% 首付,初次验收再打款 40%,终验 20%,尾保款 10%
然而除了首付,收回验收款、尾款的进程往往是很难的,主要面临三个问题:
- 产品不行
- 交付不行
- 客户领导变了
# 售后的具体定位
因为我目前在火山引擎 CSM 实习,我要明确售后的具体职责:
- 控制项目交付风险,不要发生需求变更、蔓延
- 能够及时高质量完成自己工作(完成领导派下来的活),保障项目的里程碑及时,推动项目及时上线和回款(回款是销售干,前提是活要干完)
- 交付过程中持续提高客户满意度,挖掘潜在商机,配合商务(客户成功经理,特殊销售)完成 2、3 期需求引导和商机挖掘
- 控制项目交付成本,提高利润率(比较空泛)
# 我为什么先做售后再做售前
售前工作吃技术,直接上手不稳,先成为产品专家,触类旁通的,先上手,后面更有谈资
todo: 等刀老师补充话术